Die robots.txt Datei dient dazu, das Verhalten von Crawlern zu reglementieren. Das können Suchmaschinen-Crawler wie der Googlebot oder der Apple Bot sein, aber auch Bots von Tools wie z.B. der Sistrix Crawler.
Mit dem Robots Exclusion Standard gibt es ein festes Regelwerk an Definitionen, die in der robots.txt genutzt werden können. Die bekannteste und wichtigste darunter ist die Anweisung
User-Agent: * Disallow: /
Dieses Beispiel würde dafür sorgen, das kein Crawler die Seite aufrufen darf. Und das ist der entscheidende Punkt: aufrufen.
Die Anweisung sagt nichts über die Indexierung der Seite aus. Auch wenn es lange Zeit so war, dass Google eine Seite nicht indexiert hat, wenn sie per robots.txt gesperrt war, ist es heute völlig anders: Ständig werden Seiten in den Index aufgenommen, auch wenn Google sie gar nicht aufrufen darf. Entweder Google kennt die Inhalte noch historisch von einem Zeitpunkt zu dem der Zugriff noch nicht verboten war oder sie schätzen den Inhalt hinter einer URL aufgrund der eingehenden Linksignale auf diese URL.
Dass Sperrung nicht automatisch Deindexierung bedeutet ist erwünschtes Verhalten und in vielen Fällen sinnvoll, vor allem weil die robots.txt oft falsch genutzt wird:
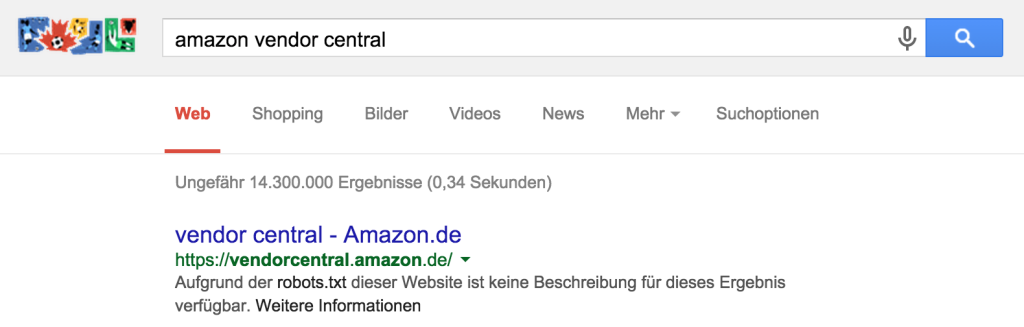
Beispiel: Amazon Vendor Central
Die Amazon Vendor Central ist Anlaufpunkt für Großhändler und Geschäftspartner von Amazon, eine ziemlich wichtige Oberfläche. Amazon hat vendorcentral.amazon.de per robots.txt für Crawler gesperrt, vermutlich weil es dort ohnehin keine großartigen Inhalte zum Crawlen gibt. Google indexiert die Seite trotzdem mit dem Hinweis
Aufgrund der robots.txt dieser Website ist keine Beschreibung für dieses Ergebnis verfügbar.
um für dieses navigationale Query trotzdem ein Ergebnis anbieten zu können. Würde Google sich anders verhalten, wäre das Nutzerbedürfnis nicht befriedigt gewesen.
Gaming the system: das Verhalten ausnutzen
Da Google u.a. auf externe Linksignale angewiesen ist, um zu erkennen, dass es hinter einer verbotenen URL wahrscheinlich rankenswerte Inhalte gibt, lässt sich das System austricksten. Die robots.txt des Wordpress Blogs von Ex-Head of Webspam Matt Cutts enthält die Anweisung, u.a. das Verzeichnis /files zu sperren.
Wenn ich nun auf eine fiktive URL in diesem Verzeichnis verlinke, nimmt Google an, dass dort Inhalte vorhanden sind und indexiert die URL, auch ohne zu wissen was sich dahinter verbirgt. Das kann zu lustigen Ergebnissen führen:
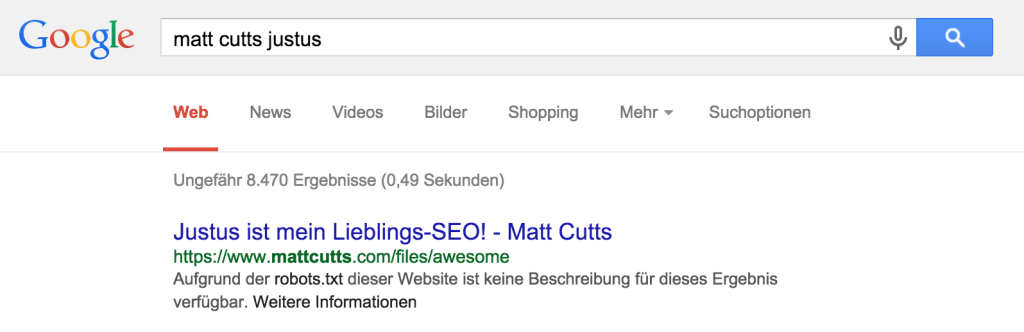 Der Titel des Suchergebnisses stammt aus dem Ankertext des Links, den ich von http://seo.justusbluemer.de/involuntary-testimonial/matt.php auf diese inhaltslose URL habe zeigen lassen. Dass sich hinter https://www.mattcutts.com/files/awesome kein Inhalt verbirgt, kann Google nicht sehen, weil sie sie nicht aufrufen dürfen.
Der Titel des Suchergebnisses stammt aus dem Ankertext des Links, den ich von http://seo.justusbluemer.de/involuntary-testimonial/matt.php auf diese inhaltslose URL habe zeigen lassen. Dass sich hinter https://www.mattcutts.com/files/awesome kein Inhalt verbirgt, kann Google nicht sehen, weil sie sie nicht aufrufen dürfen.
Funktionierende Indexsteuerung: Meta-Tags & X-Robots Header
Soll eine Seite nicht (mehr) im Google-Index erscheinen, ist der Ausschluss über die robots.txt also der falsche Weg. Eigentlich vorgesehen ist dafür das Tag
<meta name="robots" content="noindex, follow">
oder die X-Robots Angabe in der HTTP-Antwort vom Server an den Client:
X-Robots-Tag: noindex
To Do
Die robots.txt sollte bis auf einige wenige begründete Ausnahmefälle nicht mehr als diese Angaben enthalten:
User-Agent: * Disallow:
Sitemap: http://www.example.net/sitemap.xml
(Die URL der Sitemap-Angabe natürlich ausgetauscht durch den Link zu eurer eigenen XML-Sitemap)
Damit erlaubt ihr allen Crawlern, eure Seite komplett anzuschauen. Das Sperren einzelner Teile (z.B. CSS oder JavaScript) hat zur Folge, dass Google die Gestaltung eurer Seite nicht sicher bestimmen kann und möglicherweise aufgrund einer Restunsicherheit euch anders (schlechter?) rankt als ohne.